

DeepSeek春節(jié)前夕爆火,迄今熱度不減。DeepSeek徹底走開源路線,它的大模型既性能優(yōu)異,訓(xùn)練成本和使用成本又都超低,讓人工智能從業(yè)者燃起了“我也能行”的希望,讓各行各業(yè)燃起了“趕緊把人工智能用起來(lái)吧”的熱情。
伴隨著這些振奮人心的消息,也有一些真假難辨的說(shuō)法同時(shí)在流傳,例如DeepSeek顛覆了人工智能的發(fā)展方向,DeepSeek的水平已經(jīng)超過人工智能行業(yè)的領(lǐng)頭羊OpenAI;或者,DeepSeek是個(gè)巨大泡沫,它只是“蒸餾”了OpenAI的模型。
為搞清楚這些說(shuō)法,這些天我研讀了很多資料,也請(qǐng)教了一些專家,對(duì)DeepSeek究竟創(chuàng)新了什么、能否持續(xù)創(chuàng)新有了初步答案。
先說(shuō)第一個(gè)問題的結(jié)論:DeepSeek的大模型采用了更加高效的模型架構(gòu)方法、訓(xùn)練框架和算法,是巨大的工程創(chuàng)新,但不是從0到1的顛覆式創(chuàng)新。DeepSeek并未改變?nèi)斯ぶ悄苄袠I(yè)的發(fā)展方向,但大大加快了人工智能的發(fā)展速度。
為何會(huì)得出這個(gè)結(jié)論?我們需要先了解人工智能技術(shù)的發(fā)展脈絡(luò)。
人工智能簡(jiǎn)史
人工智能發(fā)端于上世紀(jì)40年代,已經(jīng)發(fā)展了近80年,奠基人是英國(guó)計(jì)算機(jī)科學(xué)家艾倫·圖林(Alan Turing)。以他的名字命名的圖林獎(jiǎng)是計(jì)算機(jī)科學(xué)界的諾貝爾獎(jiǎng)。
如今,主導(dǎo)人工智能行業(yè)的是大模型技術(shù),主導(dǎo)應(yīng)用是生成式AI——生成語(yǔ)義、語(yǔ)音、圖像、視頻。無(wú)論DeepSeek系列,還是OpenAI的GPT系列,還是豆包、Kimi、通義千問、文心一言,都屬于大模型家族。
大模型的理論基礎(chǔ)是神經(jīng)網(wǎng)絡(luò),這是一種試圖讓計(jì)算機(jī)摹仿人腦來(lái)工作的理論,該理論和人工智能同時(shí)發(fā)端,但頭40年都不是主流。20世紀(jì)80年代中后期,多層感知機(jī)模型和反向傳播算法得到完善,神經(jīng)網(wǎng)絡(luò)理論才有了用武之地。多人對(duì)此作出關(guān)鍵貢獻(xiàn),其中最為我們熟知的是去年獲得諾貝爾物理學(xué)獎(jiǎng)的杰弗里・辛頓(Geoffrey Hinton),他擁有英國(guó)和加拿大雙重國(guó)籍。
神經(jīng)網(wǎng)絡(luò)理論后來(lái)發(fā)展為深度學(xué)習(xí)理論,關(guān)鍵貢獻(xiàn)者除了被譽(yù)為“深度學(xué)習(xí)之父”的杰弗里・辛頓,還有法國(guó)人楊·勒昆(Yann LeCun,中文名楊立昆)、德國(guó)人尤爾根・施密德胡伯(jürgen schmidhuber)。他們分別提出或完善了三種模型架構(gòu)方法:深度信念網(wǎng)絡(luò)(DBN,2006)、卷積神經(jīng)網(wǎng)絡(luò)(CNN,1998)、循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN,1997),讓基于多層神經(jīng)網(wǎng)絡(luò)的機(jī)器深度學(xué)習(xí)得以實(shí)現(xiàn)。
但到此為止,都是小模型時(shí)代,DBN和RNN的參數(shù)量通常是幾萬(wàn)到幾百萬(wàn),CNN參數(shù)量最大,也只有幾億。因此只能完成專門任務(wù),比如基于CNN架構(gòu)的谷歌AlphaGo,打敗了頂尖人類圍棋手柯潔和李世石,但它除了下圍棋啥也不會(huì)。
2014年,開發(fā)AlphaGo的谷歌DeepMind團(tuán)隊(duì)首次提出“注意力機(jī)制”。同年底,蒙特利爾大學(xué)教授約書亞·本吉奧(Yoshua Bengio)和他的兩名博士生發(fā)表更詳盡的論文,這是神經(jīng)網(wǎng)絡(luò)理論的重大進(jìn)步,極大增強(qiáng)了建模能力、提高了計(jì)算效率、讓大規(guī)模處理復(fù)雜任務(wù)得以實(shí)現(xiàn)。
約書亞·本吉奧、楊·勒昆、杰弗里・辛頓一起獲得了2019年的圖林獎(jiǎng)。
2017年,谷歌提出完全基于注意力機(jī)制的Transformer架構(gòu),開啟大模型時(shí)代。迄今,包括DeepSeek在內(nèi)的主流大模型都采用該架構(gòu)。強(qiáng)化學(xué)習(xí)理論(Reinforcement Learning,RL)、混合專家模型(Mixture of Experts,MOE,又譯稀疏模型)也是大模型的關(guān)鍵支撐,相關(guān)理論均在上世紀(jì)90年代提出,21世紀(jì)10年代后期由谷歌率先用于產(chǎn)品開發(fā)。
順便澄清一個(gè)普遍誤解,MOE并不是和Transformer并列的另一種模型架構(gòu)方法,而是一種用來(lái)優(yōu)化Transformer架構(gòu)的方法。
今天的主流大模型,參數(shù)量已達(dá)萬(wàn)億級(jí),DeepSeek V3是6710億。如此大的模型,對(duì)算力的需求驚人,而英偉達(dá)的GPU芯片正好提供了算力支持,英偉達(dá)在AI芯片領(lǐng)域的壟斷地位,既讓它成為全球市值最高的公司,也讓它成為中國(guó)AI公司的痛點(diǎn)。
谷歌在大模型時(shí)代一路領(lǐng)先,但這幾年站在風(fēng)口上的并不是谷歌,而是2015年才成立的OpenAI,它的各類大模型一直被視為業(yè)界頂流,被各路追趕者用來(lái)對(duì)標(biāo)。這說(shuō)明在人工智能領(lǐng)域,看似無(wú)可撼動(dòng)的巨頭,其實(shí)并非無(wú)法挑戰(zhàn)。人工智能技術(shù)雖然發(fā)展了80年,但真正加速也就最近十幾年,進(jìn)入爆發(fā)期也就最近兩三年,后來(lái)者始終有機(jī)會(huì)。DeepSeek公司2023年7月才成立,它的母體幻方量化成立于2016年2月,也比OpenAI年輕。人工智能就是一個(gè)英雄出少年的行業(yè)。
開發(fā)出能像人一樣自主思考、自主學(xué)習(xí)、自主解決新問題的通用人工智能系統(tǒng)(Artificial General Intelligence,AGI),是AI業(yè)界的終極目標(biāo),無(wú)論奧特曼還是梁文峰,都把這個(gè)作為自己的使命。他們都選擇了大模型方向,這是業(yè)界的主流方向。
沿著大模型方向,要花多久才能實(shí)現(xiàn)AGI?樂觀的預(yù)測(cè)是3-5年,保守的預(yù)測(cè)是5-10年。也就是說(shuō),業(yè)界認(rèn)為最遲到2035年,AGI就可實(shí)現(xiàn)。
大模型的競(jìng)爭(zhēng)至關(guān)重要,大模型是各行各業(yè)人工智能應(yīng)用的最上游,它就像人的大腦,大腦指揮四肢,大腦的質(zhì)量決定整個(gè)人的學(xué)習(xí)、工作、生活質(zhì)量。
當(dāng)然,大模型并非通往AGI的唯一路徑。正如上世紀(jì)90年代后“深度學(xué)習(xí)-大模型”路線顛覆了人工智能頭幾十年的“規(guī)則系統(tǒng)-專家系統(tǒng)”路線,“深度學(xué)習(xí)-大模型”路線也有可能被顛覆,只是我們現(xiàn)在還看不到誰(shuí)會(huì)是顛覆者。
DeepSeek創(chuàng)新了什么?
如今,DeepSeek又成了挑戰(zhàn)者,它真的已經(jīng)超越OpenAI了嗎?并非如此。DeepSeek在局部超過了OpenAI的水平,但整體而言O(shè)penAI仍然領(lǐng)先。
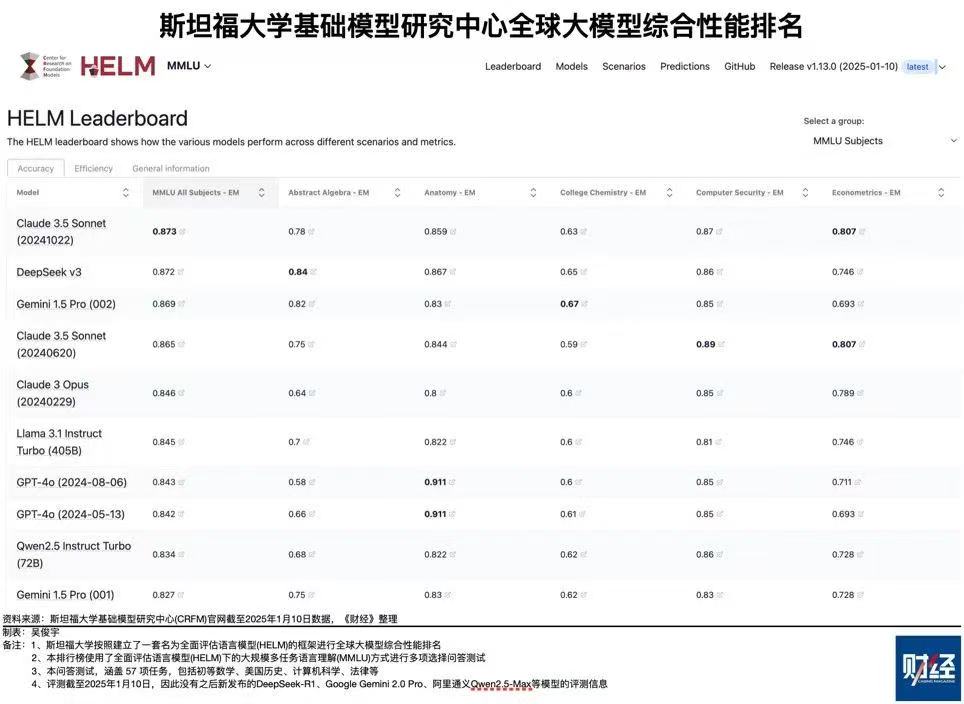
先來(lái)看雙方的基礎(chǔ)大模型,OpenAI是2024年5月發(fā)布的GPT4-o,DeepSeek是2024年12月26日發(fā)布的V3。斯坦福大學(xué)基礎(chǔ)模型研究中心有個(gè)全球大模型綜合排名,最新排名是今年1月10日,一共六個(gè)指標(biāo),各指標(biāo)得分加總后,DeepSeek V3總分4.835,名列第一;GPT4-o(5月版)總分4.567,僅列第六。第二到第五名都是美國(guó)模型,第二名是Claude 3.5 Sonnet,總分4.819,開發(fā)這個(gè)模型的Anthropic公司2021年2月才成立。
推理模型是大模型的新發(fā)展方向,因?yàn)樗乃季S模式更像人,前面說(shuō)了,開發(fā)出能像人一樣自主思考、自主學(xué)習(xí)、自主解決新問題的通用人工智能是AI業(yè)界的終極目標(biāo)。
2024年9月12 日,OpenAI發(fā)布世界上第一款推理大模型獵戶座1號(hào)(orion1 ,o1),o1在解決數(shù)學(xué)、編程和科學(xué)問題上的能力提升驚人,但OpenAI走閉源路線,不公布技術(shù)原理,更別提技術(shù)細(xì)節(jié)。一時(shí)間,如何復(fù)刻o1,成為全世界AI從業(yè)者的追求。
僅僅四個(gè)月后,今年1月20日,DeepSeek發(fā)布世界第二款推理大模型R1,名字樸實(shí)無(wú)華,R就是推理(Reasoning)的縮寫。測(cè)評(píng)結(jié)果顯示,DeepSeek-R1與OpenAI-o1水平相當(dāng)。但OpenAI 2024年12月20日推出了升級(jí)版o3,性能大大超過o1。目前還沒有R1和o3的直接測(cè)評(píng)對(duì)比數(shù)據(jù)。
多模態(tài)也是大模型的重要發(fā)展方向——既能生成語(yǔ)義(寫代碼也屬于語(yǔ)義),也能生成語(yǔ)音、圖像、視頻,其中視頻生成最難,消耗的計(jì)算資源最多。DeepSeek 2024年10月發(fā)布首個(gè)多模態(tài)模型Janus,今年1月28日發(fā)布其升級(jí)版Janus-Pro-7B,其圖像生成能力在測(cè)試中表現(xiàn)優(yōu)異,但視頻能力如何尚無(wú)從知曉。GPT-4是多模態(tài)模型但不能生成視頻,不過OpenAI擁有專門的視頻生成模型Sora。
把模型做小做精,少消耗計(jì)算資源是另一個(gè)業(yè)界趨勢(shì),混合專家模型的設(shè)計(jì)思路就是這個(gè)目的,推理模型也能減少通用大模型的驚人消耗。在這方面,DeepSeek的表現(xiàn)明顯比OpenAI優(yōu)異,這些天最被人津津樂道的就是DeepSeek的模型訓(xùn)練成本只有OpenAI的1/10,使用成本只有1/30。DeepSeek能夠做到如此高的性價(jià)比,是因?yàn)樗哪P屠锩嬗薪艹龅墓こ虅?chuàng)新,不是單點(diǎn)創(chuàng)新,而是密集創(chuàng)新,每一個(gè)環(huán)節(jié)都有杰出創(chuàng)新。這里僅舉三例。
★模型架構(gòu)環(huán)節(jié):大為優(yōu)化的Transformer + MOE組合架構(gòu)。
前面說(shuō)過,這兩個(gè)技術(shù)都是谷歌率先提出并采用的,但DeepSeek用它們?cè)O(shè)計(jì)自己的模型時(shí)做了巨大優(yōu)化,并且首次在模型中引入多頭潛在注意力機(jī)制(Multi-head Latent Attention,MLA),從而大大降低了算力和存儲(chǔ)資源的消耗。
★模型訓(xùn)練環(huán)節(jié):FP8混合精度訓(xùn)練框架。
傳統(tǒng)上,大模型訓(xùn)練使用32位浮點(diǎn)數(shù)(FP32)格式來(lái)做計(jì)算和存儲(chǔ),這能保證精度,但計(jì)算速度慢、存儲(chǔ)空間占用大。如何在計(jì)算成本和計(jì)算精度之間求得平衡,一直是業(yè)界難題。2022年,英偉達(dá)、Arm和英特爾一起,最早提出8位浮點(diǎn)數(shù)格式(FP8),但因?yàn)槊绹?guó)公司不缺算力,該技術(shù)淺嘗輒止。DeepSeek則構(gòu)建了FP8 混合精度訓(xùn)練框架,根據(jù)不同的計(jì)算任務(wù)和數(shù)據(jù)特點(diǎn),動(dòng)態(tài)選擇FP8或 FP32 精度來(lái)進(jìn)行計(jì)算,把訓(xùn)練速度提高了50%,內(nèi)存占用降低了40%。
★算法環(huán)節(jié):新的強(qiáng)化學(xué)習(xí)算法GRPO。
強(qiáng)化學(xué)習(xí)的目的是讓計(jì)算機(jī)在沒有明確人類編程指令的情況下自主學(xué)習(xí)、自主完成任務(wù),是通往通用人工智能的重要方法。強(qiáng)化學(xué)習(xí)起初由谷歌引領(lǐng),訓(xùn)練AlphaGo時(shí)就使用了強(qiáng)化學(xué)習(xí)算法,但是OpenAI后來(lái)居上,2015年和2017年接連推出兩種新算法TRPO(Trust Region Policy Optimization,信任區(qū)域策略優(yōu)化)和PPO (Proximal Policy Optimization,近端策略優(yōu)化),DeepSeek更上層樓,推出新的強(qiáng)化學(xué)習(xí)算法GRPO( Group Relative Policy Optimization 組相對(duì)策略優(yōu)化),在顯著降低計(jì)算成本的同時(shí),還提高了模型的訓(xùn)練效率。

(GRPO算法公式。Source:DeepSeek-R1論文)
看到這里,對(duì)于“DeepSeek只是‘蒸餾’了OpenAI模型”的說(shuō)法,你肯定已經(jīng)有了自己的判斷。但是,DeepSeek的創(chuàng)新是從0到1的顛覆式創(chuàng)新嗎?
顯然不是。顛覆式創(chuàng)新是指那種開辟了全新賽道,或?qū)е录扔匈惖缽氐邹D(zhuǎn)向的創(chuàng)新。比如,汽車的發(fā)明顛覆了交通行業(yè),導(dǎo)致馬車行業(yè)消失;智能手機(jī)取代功能手機(jī),雖沒有讓手機(jī)行業(yè)消失,但徹底改變了手機(jī)的發(fā)展方向。
回顧人工智能簡(jiǎn)史,我們清楚看到,DeepSeek是沿著業(yè)界的主流方向前進(jìn),他們做了許多杰出的工程創(chuàng)新,縮短了中美AI的差距,但仍處于追趕狀態(tài)。白宮人工智能顧問大衛(wèi)·薩克斯(David Sacks)評(píng)價(jià)說(shuō):DeepSeek-R1讓中美的差距從6-12月縮短到3-6個(gè)月。
薩克斯說(shuō)的是模型性能,但更加意義非凡的是性價(jià)比——訓(xùn)練成本1/10、使用成本1/30,這讓尖端AI技術(shù)飛入尋常百姓家成為現(xiàn)實(shí)。最近兩周,各行各業(yè)的領(lǐng)頭羊紛紛接入DeepSeek大模型,部署本行業(yè)的應(yīng)用,擁抱AI的熱情前所未有。
但我必須再次提醒,大模型技術(shù)進(jìn)步很快,不能對(duì)階段性成果過于樂觀。同時(shí)大模型在人工智能生態(tài)中處于最上游,是所有下游應(yīng)用的依托,因此基礎(chǔ)大模型的質(zhì)量決定了各行各業(yè)人工智能應(yīng)用的質(zhì)量。
DeepSeek能否持續(xù)創(chuàng)新?
在DeepSeek的刺激下,薩姆·奧特曼(Sam Altman)2月13日透露了OpenAI 的發(fā)展計(jì)劃:未來(lái)幾周內(nèi)將發(fā)布GPT-4.5,未來(lái)幾個(gè)月內(nèi)發(fā)布GPT-5。GPT-5將整合推理模型o3的功能,是一個(gè)包含語(yǔ)義、語(yǔ)音、可視化圖像創(chuàng)作、搜索、深度研究等多種功能的多模態(tài)系統(tǒng)。奧特曼說(shuō),今后用戶不用再在一大堆模型中做選擇,GPT-5 將完成所有任務(wù),實(shí)現(xiàn)“魔法般的統(tǒng)一智能”。果如所言,GPT-5離通用人工智能就又進(jìn)了一步。
從用戶角度,一個(gè)模型解決所有需求肯定大為方便,就像早年手機(jī)只能打電話,你出門還得帶銀行卡、購(gòu)物卡、交通卡等一大堆東西,現(xiàn)在一部智能手機(jī)全搞定。但全搞定的同時(shí),所需要的計(jì)算資源也會(huì)高得驚人,iPhone16的算力是當(dāng)年功能機(jī)的幾千萬(wàn)倍。奇跡在于,我們使用iPhone16的成本反而比使用諾基亞8210的成本更低。希望這樣的奇跡也能發(fā)生在人工智能行業(yè)。
除了OpenAI,美國(guó)還有眾多頂尖人工智能公司,他們的水平差距不大。從前面講到的那個(gè)斯坦福大學(xué)排名就能看出來(lái),總分第一名和第十名的分差只有0.335,平均到每個(gè)指標(biāo)差距不到0.06。并且各種測(cè)評(píng)榜的排名雖是重要參考,但不等于實(shí)際能力的高下。對(duì)DeepSeek而言,不僅OpenAI,Anthropic、谷歌、Meta、xAI也都是強(qiáng)勁對(duì)手。2月18日,xAI發(fā)布了馬斯克自稱“地球最強(qiáng)AI”的大模型Grok-3。這個(gè)模型用了超過10萬(wàn)塊H100芯片來(lái)訓(xùn)練,把大模型的scaling law(規(guī)模法則,計(jì)算和數(shù)據(jù)資源投入越多模型效果越好)推向極致,但也讓scaling law的邊際效益遞減暴露無(wú)遺。
當(dāng)然,中國(guó)也不是DeepSeek一家在戰(zhàn)斗,中國(guó)也有眾多優(yōu)秀人工智能公司。事實(shí)上,這些年來(lái)全球人工智能一直是中美雙峰并峙,只是美國(guó)那座峰更高一些。
盡管如此,我對(duì)梁文峰和DeepSeek團(tuán)隊(duì)仍有信心。從梁文峰為數(shù)不多的采訪中可以看出,他是一個(gè)既充滿理想主義,又腳踏實(shí)地、有敏銳商業(yè)頭腦的人。他自己肯定懂技術(shù),但應(yīng)該不是技術(shù)天才,他有可能是喬布斯、馬斯克那樣能把技術(shù)天才聚集在一起做出偉大產(chǎn)品的技術(shù)型企業(yè)家。
梁文峰在接受《暗涌》專訪時(shí)說(shuō):“我們的核心技術(shù)崗位,基本以應(yīng)屆和畢業(yè)一兩年的人為主。我們選人的標(biāo)準(zhǔn)一直都是熱愛和好奇心。招人時(shí)確保價(jià)值觀一致,然后通過企業(yè)文化來(lái)確保步調(diào)一致。”
“最重要的是參與到全球創(chuàng)新的浪潮里去。過去三十多年IT浪潮里,我們基本沒有參與到真正的技術(shù)創(chuàng)新里。大部分中國(guó)公司習(xí)慣follow(追隨),而不是創(chuàng)新。中國(guó)AI和美國(guó)真正的gap(差距)是原創(chuàng)和模仿。如果這個(gè)不改變,中國(guó)永遠(yuǎn)只能是追隨者。”
“創(chuàng)新首先是一個(gè)信念問題。為什么硅谷那么有創(chuàng)新精神?首先是敢。我們?cè)谧鲎铍y的事。對(duì)頂級(jí)人才吸引最大的,肯定是去解決世界上最難的問題。”
喬布斯有句名言:只有瘋狂到認(rèn)為自己可以改變世界的人才能改變世界。從梁文峰身上,我看到了這句話的影子。
但是,我們對(duì)中國(guó)AI超越美國(guó)千萬(wàn)不能盲目樂觀,DeepSeek并沒有顛覆算力算法數(shù)據(jù)三要素的大模型發(fā)展路徑,DeepSeek的很多創(chuàng)新都是因?yàn)樾酒芟薅坏貌粸椋热缬ミ_(dá)H100的通信帶寬是每秒900GB,H800就只有每秒400GB,但DeepSeek只能用H800來(lái)訓(xùn)練模型。
這些天我看了大量太平洋兩岸對(duì)DeepSeek的評(píng)論,“necessity is the mother of invention(迫不得已是創(chuàng)新之母)”,這句源自古希臘的諺語(yǔ)被不同的牛人說(shuō)了好幾次。但是反過來(lái)想,DeepSeek能與OpenAI的同款產(chǎn)品打成平手,靠的是用逼出來(lái)的算法優(yōu)勢(shì)彌補(bǔ)算力劣勢(shì),可對(duì)手已被點(diǎn)醒,如果他們開發(fā)出同樣好的算法,再加上更好的芯片,那中美大模型的差距是否會(huì)再次擴(kuò)大?
另一方面,雖然DeepSeek已可適配國(guó)產(chǎn)芯片,但考慮到性能差距,算力劣勢(shì)短期內(nèi)無(wú)解。除非我們能再現(xiàn)電動(dòng)車反轉(zhuǎn)燃油車的場(chǎng)面,實(shí)現(xiàn)換道超車。比如,用量子芯片替代硅基芯片。
陷入這種思考真是一個(gè)悲劇——技術(shù)創(chuàng)新本應(yīng)造福全人類,卻被地緣政治因素扭曲。所以,我們更應(yīng)該為DeepSeek堅(jiān)決走開源路線而鼓掌。
行業(yè)是最典型的新質(zhì)生產(chǎn)力代表")
濟(jì)2025:助力中國(guó)經(jīng)濟(jì)騰飛,成就高質(zhì)量發(fā)展")
年終盤點(diǎn)")
字科技生態(tài)大會(huì)")
光電纜優(yōu)質(zhì)供應(yīng)商評(píng)選活動(dòng)")